
Situering
Het gebruik van artificiële intelligentie in hedendaagse software groeit pijlsnel. Voor allerlei taken, zoals automatische classificatie van beelden, het capteren en interpreteren van allerlei signalen van de gebruiker (bijvoorbeeld bewegingen en interacties met objecten), het aansturen van automatische chatbots en het uitvoeren van machine translation, wordt er gebruik gemaakt van complexe algoritmes uit domeinen als machine learning, computer vision, planning en knowledge reasoning. Dit leidt echter tot twee prominente problemen: (1) voor softwareontwikkelaars zonder diepgaande expertise in deze domeinen is het moeilijk om de juiste algoritmes te kiezen en zeer uitdagend om een algoritme op de juiste manier aan te sturen (bijvoorbeeld feature selection uit sensor data), en (2) voor gebruikers van de software gedragen de algoritmes zich vaak als “black boxes” die gebruik maken van allerlei gebruikersdata zonder de gebruikers daarover te informeren. Beide problemen zijn uiteraard sterk gelinkt aan elkaar: de gebruiker van een AI algoritme – of dat nu een ontwikkelaar is of een eindgebruiker van de software – moet bewust gemaakt worden van de werking van het achterliggende AI algoritme en de juiste handvatten aangeboden krijgen om er controle over te verwerven. Een recent onderzoeksdomein dat hierop inspeelt is eXplainable Artificial Intelligence (XAI).
In dit project brengen we XAI in kaart voor ontwikkelaars, beslissingsnemers en eindgebruikers. Gezien de bruikbaarheid, begrijpelijkheid (ook wel ‘intelligibility’ genoemd) en controle van een AI-gebaseerd systeem in belangrijke mate bijdraagt aan de acceptatie en het nut van deze technologie, is het belangrijk dat de Vlaamse industrie deze aspecten eenvoudig kan optimaliseren binnen hun AI oplossingen. Teneinde een werkbare scope te verkrijgen, focussen we op een specifiek aantal klassen van machine learning algoritmes. Initieel zullen we oplossingen voorzien voor software die gebruik maakt van neurale netwerken, statistische modellen, of decision trees. Afhankelijk van de cases die door de industriële partners van dit project worden aangeleverd, kunnen andere klassen van algoritmes toegevoegd worden.
Resultaten
In een eerste fase werd er een verzameling gemaakt van papers met betrekking tot het gebruik van (X)AI. Deze is raadpleegbaar via Airtable.
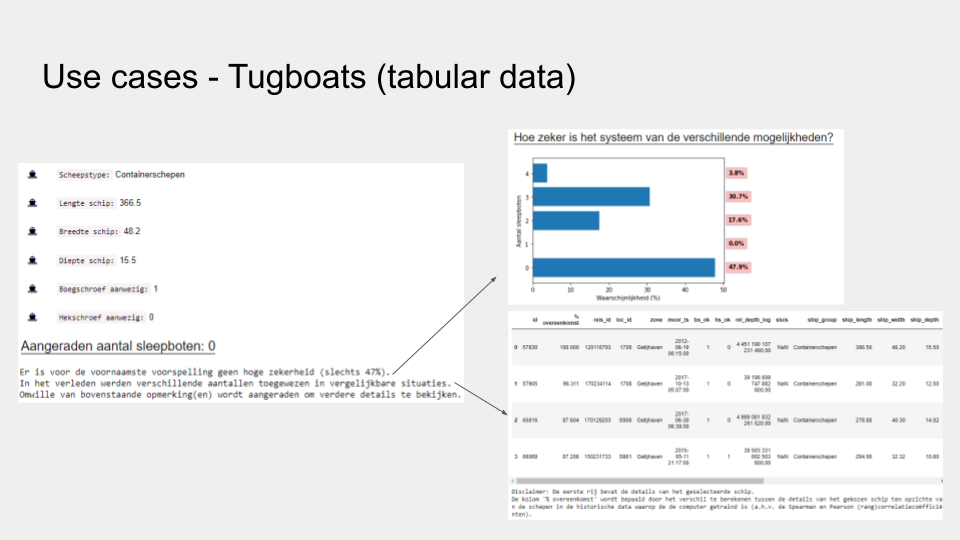
Onze eerste demonstrator betreft scheepsdata van een haven, waar grote schepen in de haven geleid moeten worden met sleepboten. De data bevat verschillende scheepskarakteristieken en externe factoren, zoals windrichting en -snelheid, die invloed kunnen hebben op hoeveel sleepboten nodig zijn om een schip te begeleiden. AI kan hier advies bieden over het aantal benodigde sleepboten. XAI zorgt voor extra informatie, zoals welke karakteristieken het meeste invloed hadden op dit advies, zodat er een geïnformeerde beslissing genomen kan worden. Op deze manier kunnen overtrust en undertrust in het systeem vermeden worden.
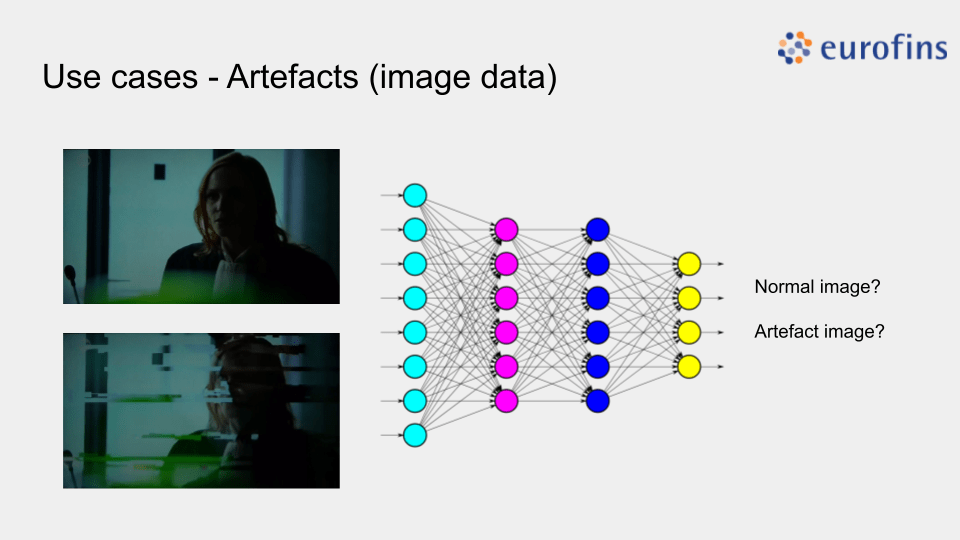
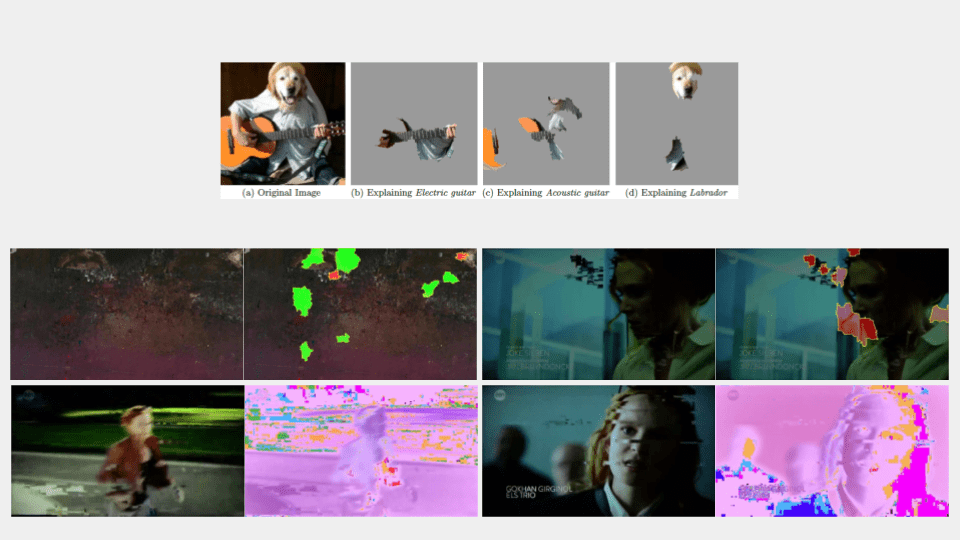
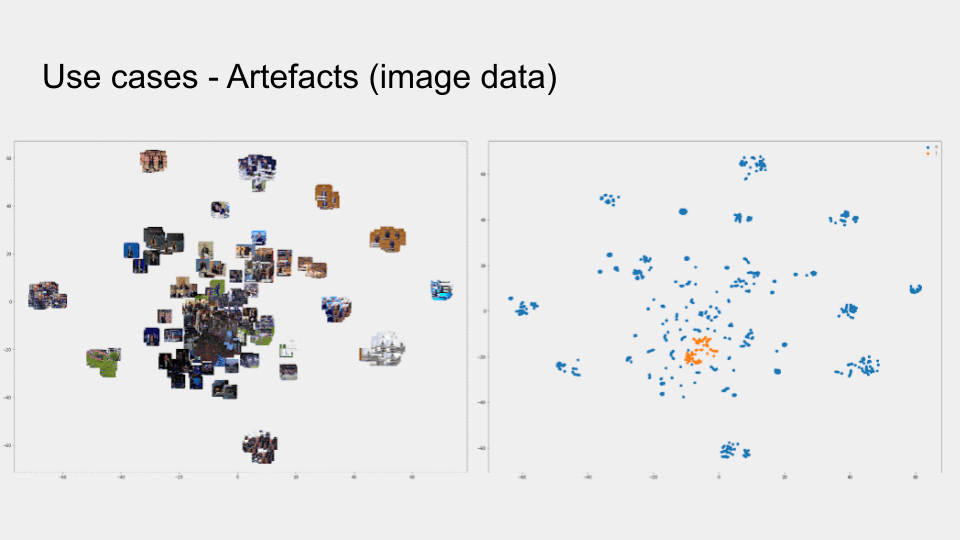
Onze tweede demonstrator betreft beeldgegevens, waarbij een AI model beelden classificeert als een ‘normaal’ beeld of een beeld dat artefacten (storingen) bevat. Met XAI krijgen eindgebruikers en ontwikkelaar hier meer inzicht door de aanduiding van welke pixels de meeste impact hebben gegeven bij de classificatie. Dit in meerdere vormen, waarbij een eerste aanduiding gegenereerd wordt volgens een model explanation approach dat de werking van het globale complexe model probeert de benaderen en anderzijds via model inspection, dat heatmaps van pixels of interest genereert voor het oorspronkelijk beeld.
Daarnaast werd er ook ingezet op een unsupervised learning sidetrack, waarbij een autoencoder getraind werd met juiste beelden, waarna artefacten met een te grote reconstructiefout als artefact gelabeld konden worden. Explainability werd toegevoegd door de latent space te verkennen (typische eigenschap van autoencoders) en hoe alle samples in een 2D-ruimte worden geprojecteerd.

Onze derde demonstrator betreft de chatbot dAIsy, om met een zichzelf verklarende NLP-chatbot de database aan papers te verkennen. Dit om eindgebruikers die op zoek zijn naar welbepaalde papers de meest op de vraag aansluitende papers aan te raden. Bovendien verkrijgt de eindgebruiker de optie om een NLP-gegenereerde samenvatting van een paper te lezen, om te bepalen of het aansluit bij wat de gebruiker zoekt. Deze gegenereerde samenvatting wordt op haar beurt ook verklaarbaar gemaakt, door aan te duiden welke termen in de paper het meest hebben bijgedragen tot het genereren van de samenvatting.
Meer weten?
Voor meer info, contacteer robin.schrijvers@pxl.be (Hogeschool PXL – PXL Smart ICT) of davy.vanacken@uhasselt.be (Universiteit Hasselt – EDM).